Loading...
MLSystems EngineeringResearch
The fastest LLM request scheduler for agent systems
The fastest LLM request scheduler for agent systems
Loading...
AgentIR is a predictive LLM request scheduler for agent systems. It sits between agent builders and LLM providers, takes user supplied agent system code, compiles it into an intermediate representation, and uses that structure as runtime hints for online scheduling. The goal is simple: treat an agent as a workflow, not as a bag of independent calls, and use that workflow context to reduce end to end latency and improve throughput on the same underlying model servers. The result is scheduling that reduces average graph latency by 41.3% compared to round robin scheduling, and by 21.0% compared to SOTA scheduling systems.
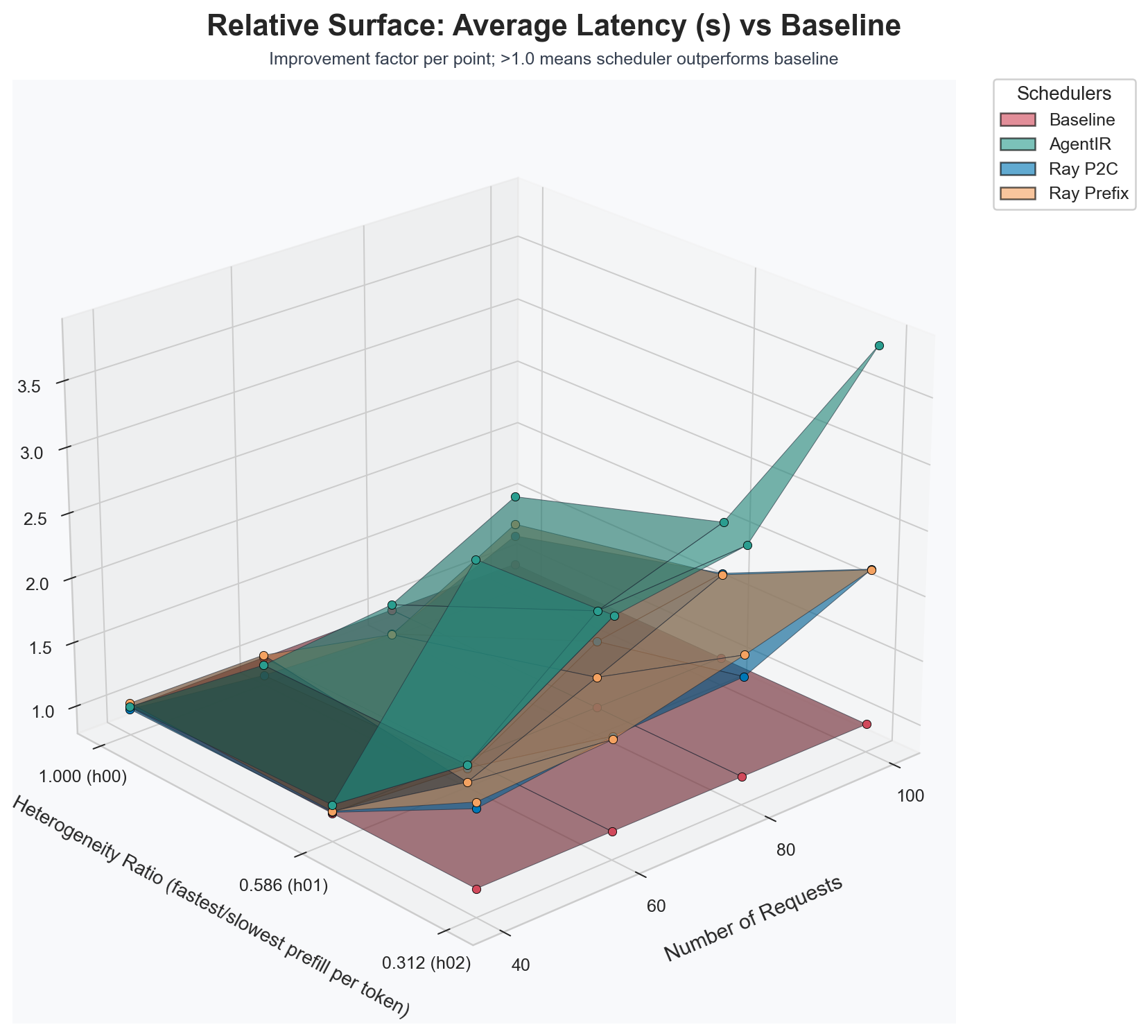
Figure 1: Relative average request latency comparison.
You can make agents run meaningfully faster without changing the underlying models.
Agents are workflows, not calls, so we should schedule them like workflows.
Any performance problem can be solved by removing a level of indirection. — M. Haertel: Butler Lampson, Hints and Principles for Computer System Design, 2021. https://arxiv.org/pdf/2011.02455
The core observation is that current agent execution patterns introduce indirection between the structure of the workload and the scheduling decisions that determine its performance. Agent frameworks encode structure in the form of a dependency graph with dynamic control flow. Meanwhile, most serving stacks still make placement decisions at the granularity of current requests, with limited visibility into what else is going to arrive. When scheduling decisions are made without that workflow context, the system often commits early and then regrets the decision later, not because the scheduler is weak, but because it is missing the right boundary to optimize against.
AgentIR occupies that boundary. It operates as a control plane that routes and coordinates requests across heterogeneous vLLM instances as one coherent workflow execution plan.
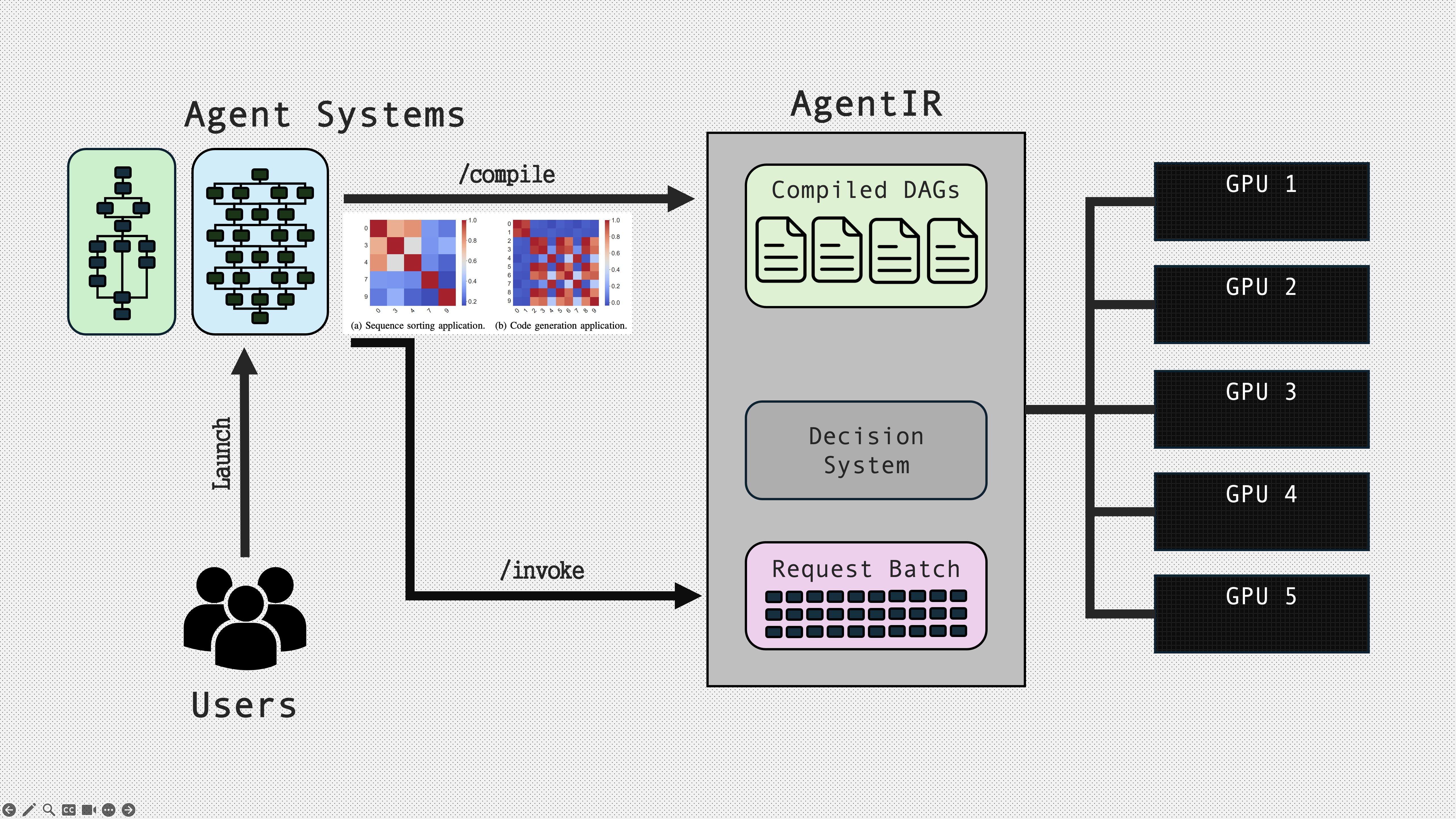
Figure 2: AgentIR system architecture diagram.
AgentIR takes user supplied agent system code and compiles it into a dependency graph. That representation is not an offline schedule. It is a compact description of the structure that the scheduler can consult while making online placement and timing decisions at runtime. AgentIR then executes the full workflow across heterogeneous LLM instances as one coordinated plan. Heterogeneity is an explicit target, including differences in model size, GPU type, and concurrency limits.
A common failure mode in request routing is scheduler regret. A request arrives, the scheduler routes it to the best looking instance under current load, and the decision is committed. Moments later, coupled follow on requests arrive, and the system realizes the earlier placement made the critical path worse, missed a batching opportunity, or trapped work behind a queue that is about to become a straggler. This is not a bug. It is the predictable outcome of making locally optimal decisions without enough information about the near future workload.
Figure 3: Scheduler regret caused by limited future visibility.
AgentIR reduces regret by extracting future information from the workflow itself. The key advantage is that a workflow representation implies future demand before it materializes at the serving boundary. Many of the next requests are structurally implied by the graph and are partially predictable, including which node is likely to run next, which static prompts will prefix the request, and which tool calls may introduce latency gaps. AgentIR uses this implied future demand to make online placement decisions that minimize expected E2E workflow latency.
This scheduling objective: minimize expected workflow completion time for each workflow invocation, while maintaining good throughput under load.
AgentIR uses a lightweight annotation library that can be added directly to LangGraph nodes. The intent is to keep annotation overhead low while exposing the minimum structure needed for effective scheduling.
A fully annotated node can look like this:
@writes("summarizer_line", "messages")
@llm_call(model="llama-8b", reads=["composer_line"], static_vars=["SUMMARIZER_SYSTEM_PROMPT"])
def summarizer(state: DocState, config=None):
...
A minimal annotation is smaller:
@llm_call(model="llama-8b", static_vars=["SUMMARIZER_SYSTEM_PROMPT"])
def summarizer(state: DocState, config=None):
...
In practice, the minimal form tells AgentIR that the node corresponds to an LLM request and identifies static prompt components that shape the request prefix. Optional read and write annotations can be provided when the scheduler should understand asynchronous structure, data dependencies, and join behavior more precisely. Conditional branches are supported, and branch probabilities can be learned over time from observed executions.
Through this branch prediction system, AgentIR might not be limited to explicit graph based frameworks. For ReAct style agents, where the control flow is expressed implicitly through an evolving sequence of LLM calls and tool invocations, AgentIR could learn a probabilistic workflow model directly from execution traces. Concretely, it will record historical call sequences, tool choice patterns, and branching frequencies, and uses these statistics to infer a latent structure that approximates a dependency graph with uncertain edges. This is motivated by recent work on scheduling compound LLM applications under structural uncertainty, which models an application as an uncertain graph shaped by runtime decisions and then schedules using that probabilistic structure (Scheduling Compound LLM Applications Under Structural Uncertainty [4]).
AgentIR operates at the serving boundary, whereas prior work focuses on stage ordering under uncertainty. LLMSched relies on simple executor load balancing and does not model heterogeneous instances, prefix locality, or batching as scheduling levers. AgentIR incorporates these factors directly, enabling lower tail latency, particularly P95 end-to-end workflow latency.
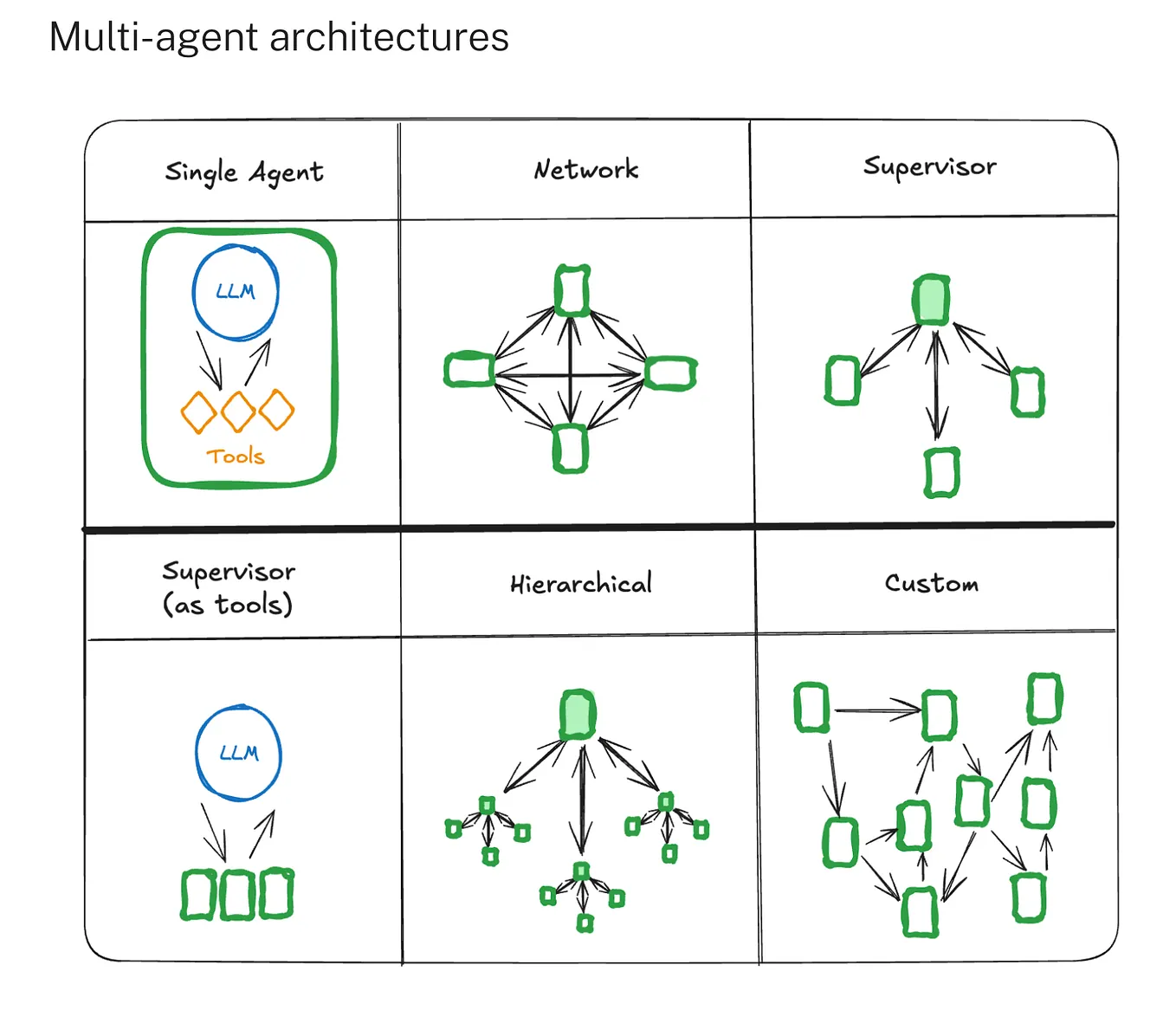
Figure 4: Multi-agent architecture patterns represented as dependency graphs.
At runtime, AgentIR combines workflow structure with live telemetry. It profiles instances online, learns latency functions for prefill and decode behavior, and uses token length predictions and tool delay estimates to improve completion time estimates. It also maintains probabilistic models for conditional edges, analogous in spirit to branch prediction, but grounded in observed workflow execution probabilities. These signals are used to prioritize and place nodes in a way that reduces expected stalls at joins and reduces the probability that a late node becomes the bottleneck for the entire graph.
AgentIR is designed to keep dispatch overhead negligible. Planning can involve nontrivial reasoning, but dispatch is amortized with respect to scheduler load: when an LLM request is ready to run, the scheduler can route it through a fast decision path rather than recomputing expensive logic. The practical implication is that a more informed scheduler does not need to be a slower scheduler. This matters because any scheduling overhead that scales with graph complexity can erase latency gains.
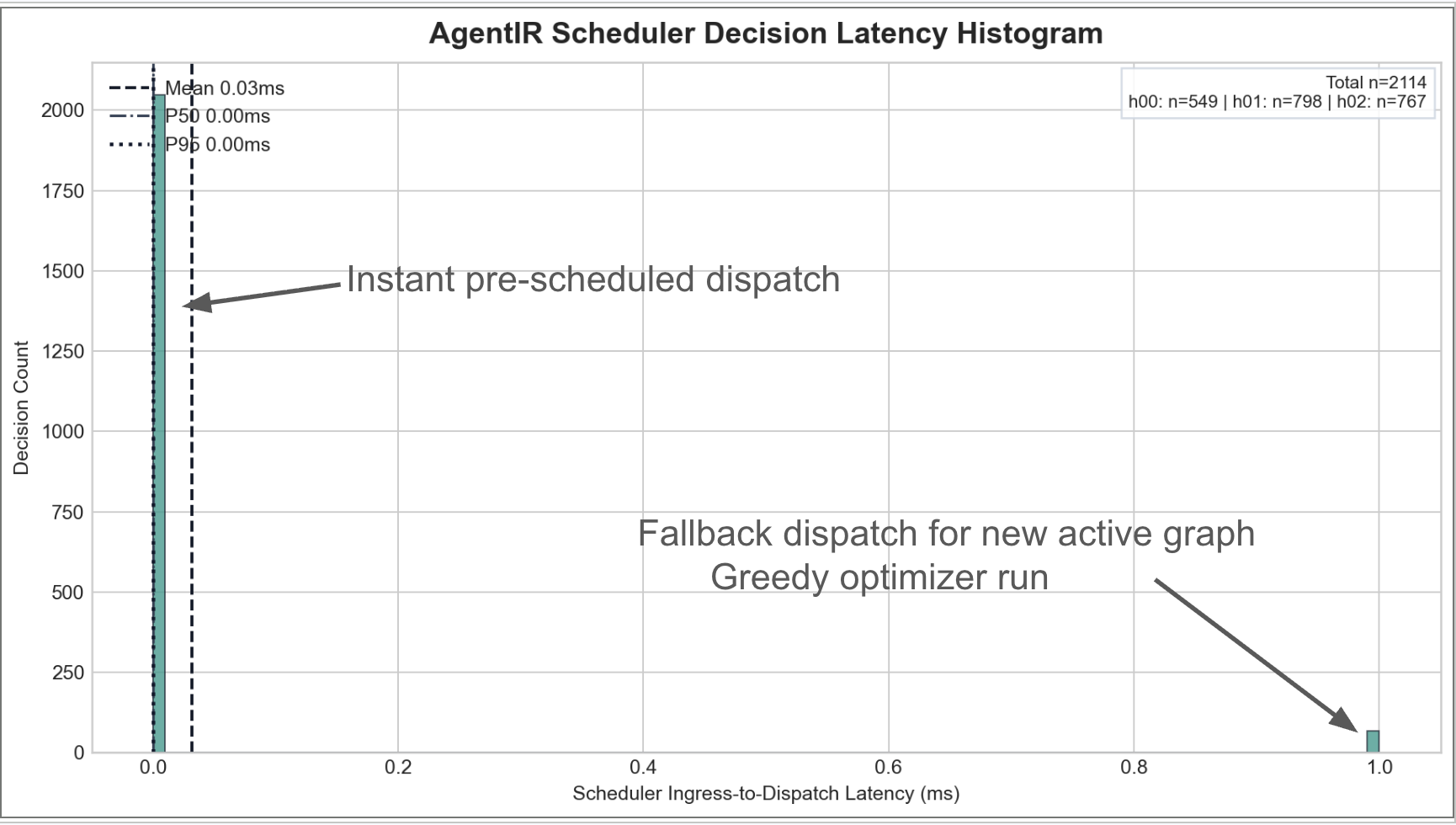
Figure 5: Histogram of dispatch latency in AgentIR.
AgentIR also exploits prompt prefix locality. vLLM implements automatic prefix caching by caching KV blocks for processed prompts and reusing them when a new request arrives with the same prefix. ([vLLM][2]) Ray Serve provides prefix aware routing that tracks prefixes processed by replicas and routes requests with similar prefixes to the same replicas to improve cache hit rates. ([Ray][3])
AgentIR builds on this ecosystem in a workflow aware way. Since the intermediate representation can identify which workflow node generated a request, AgentIR can co schedule requests originating from the same node across many invocations, increasing the probability of prefix reuse on the same instance. This is one of several locality signals the planner can consider alongside critical path effects and queue dynamics.
For benchmarking and reproducibility, see the AgentIR testing harness. The benchmark workload is a production style LangGraph workflow with parallel branches and conditional routing, creating a nontrivial dependency graph that stresses scheduling, queueing, and cache locality.
Evaluation is performed on 5 simulated vLLM instances. Heterogeneity of the system is measured by taking the min prefill per token latency / max prefill per token latency. h00 is least heterogeneous while h02 is the most heterogeneous.
Results are reported using average workflow completion time (Average Latency (s)), alongside supporting metrics such as tail latency (P95 Latency (s)), and graph throughput (Average Throughput (graphs/s)). Per call latency is mostly unmeasured, since the user experience of an agent system is determined by the time to finish the whole graph, not the time of any single node.
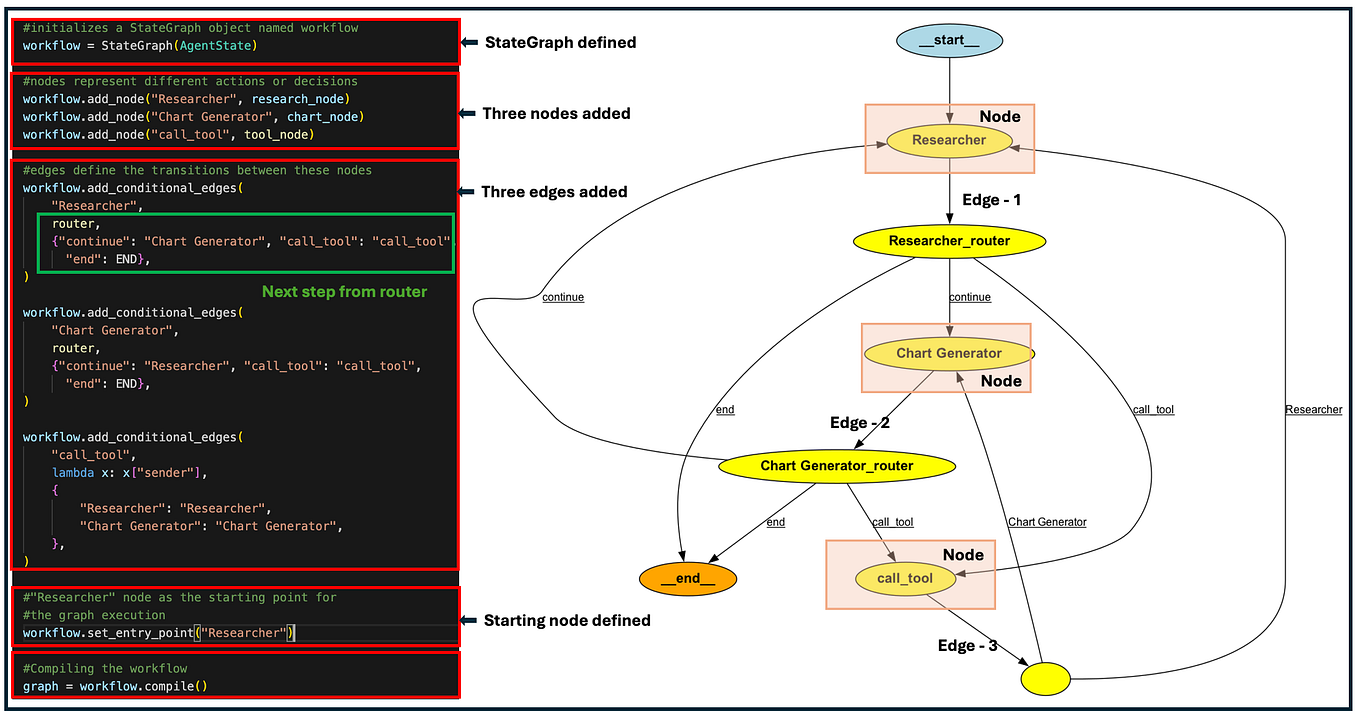
Figure 6: LangGraph code compiled into an execution graph.
Baselines are a simple round robin scheduler, Ray Serve Power of 2 Choices, and Ray Serve PrefixCacheAffinityRouter.
AgentIR reduces average E2E graph latency (41.3% vs round-robin; 21.5% vs Ray P2C; 20.5% vs Ray Prefix) and improves throughput (70.5% vs round-robin; 27.4% vs Ray P2C; 26.5% vs Ray Prefix) relative to current state of practice request schedulers.
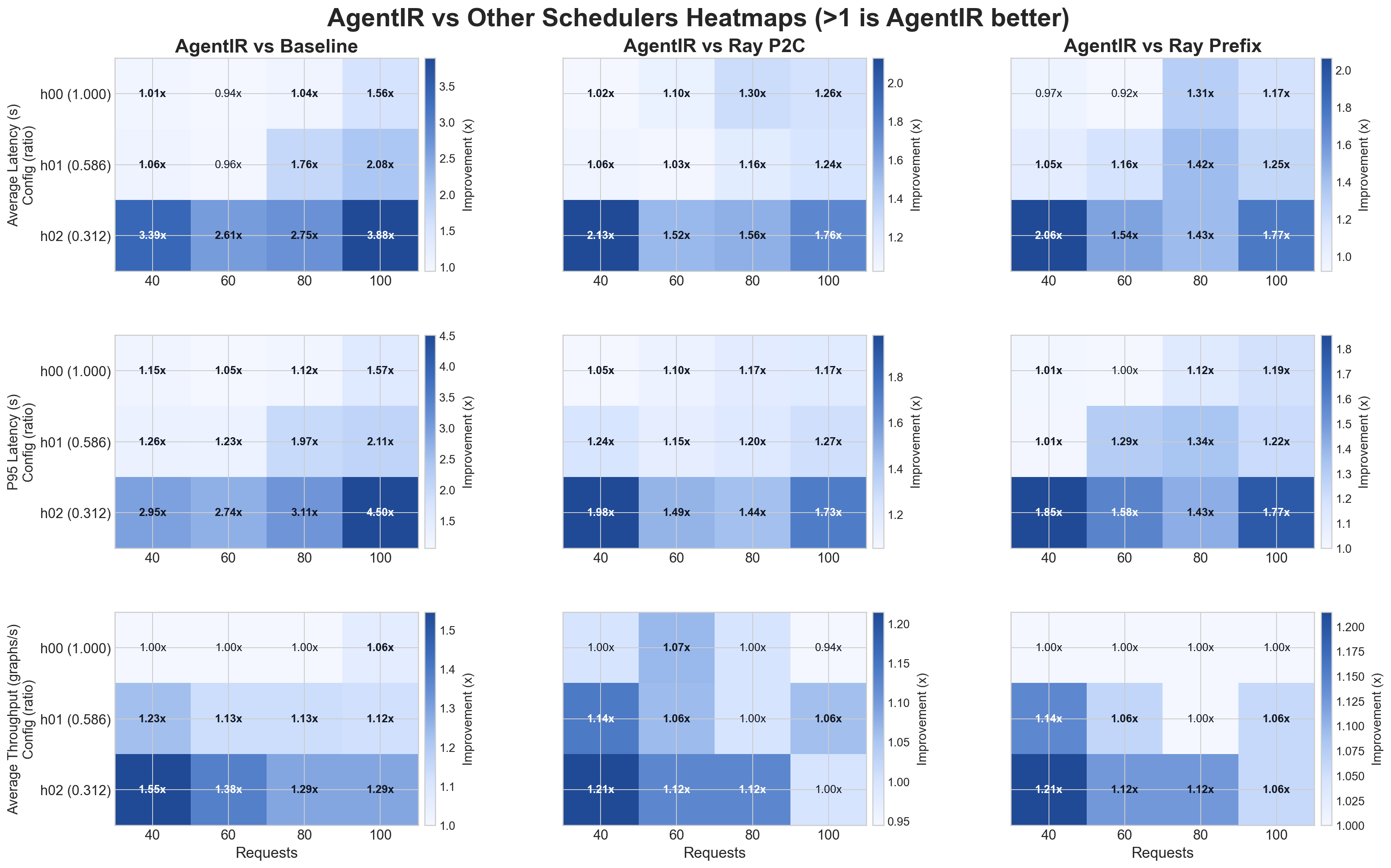
Figure 7: E2E graph latency and throughput results vs baseline and Ray Serve schedulers.
It is observed that AgentIR performs significantly better than existing systems on highly heterogeneous systems.
For providers, AgentIR represents a way to offer an agent execution endpoint that is purpose built for agent workloads while keeping the underlying serving stack intact. The provider retains control of the fleet and benefits from workflow level scheduling and telemetry driven modeling. Agent builders retain their development workflow and gain performance without hand tuning low level scheduling decisions that they cannot realistically control.
The opportunity is clear. Agent execution today inserts a gap between workflow structure and request scheduling. AgentIR shrinks that gap by scheduling with workflow context, and the result is faster agents without changing models.